

You click “Sign in with Google” and grant permission to read your Google Calendar. You made that decision at that moment in time, and now the meeting scheduling tool has the ability to access your calendar data within Google. You weighed it up, decided you wanted the feature and committed to the action.
Behind the scenes, the application receives a token and calls Google on your behalf to retrieve the data, but the action is in your name. This is the contract OAuth was built to serve, because without it you would need to share your Google login details with any tool you want to give access to. The click was the consent; the token was the receipt.
OAuth solved credential delegation, not autonomous decision-making. In the world of autonomous AI agents, things are a little different. The token may still prove you have valid access, but it no longer proves who made the decision to access or modify your data.
Intent is now autonomous
OAuth works because a human is at the keyboard at the moment of consent and, typically, at the moment of action. There was an unspoken assumption when you granted access to the tool, you assumed that it would not “delete your calendar data” because that instruction would have to come from you. Some people would be careful and read what permissions were being granted, others would just click through. However, it was largely safe because the user remained the source of authority.
Autonomous AI agents also need access to data, perhaps your calendar data, or perhaps essential RBAC-governed data at the core of your enterprise. But when does the click and consent happen? Currently, the user authorises the agent once, at deployment, to act on their behalf indefinitely. The rest is over to the agent: it reasons and acts.
The core difference is when intent occurs. Autonomous agents are useful because they form executable intent. They decide that sending a follow-up email to someone who did not respond is the correct thing to do. The agent is useful precisely because it can do that. It is useful because it can turn a broad objective into specific actions the user did not have to define themselves. The whole commercial argument for agentic AI sits on top of this. Strip it out and you no longer have an agent; you are back to a SaaS application or classic automation.
How does OAuth account for this shift? Currently, it does not.
Enforcement within the agent isn’t enough
There is a tendency in many agent-based systems to try to control the agent using a few different approaches. The first is the idea that we can prompt our way to compliance. We ask the model, or LLM, backing the agent to do only certain things. For example, we add to our prompt:
NEVER DELETE ALL OF MY EMAILS
What this means is that when the agent drives the tools that give it purpose, the LLM should never request a call to the tool or API that deletes all your emails. However, a lot of people will be familiar with LLM hallucinations, misalignment and prompt injection. As I’ve discussed before, here, we cannot rely on this strategy to safeguard against unexpected or disastrous situations.
Another approach uses restrictions within the agent, or “harness”, to introduce deterministic controls. This is an approach that users of Claude products such as Cowork or Claude Code will be familiar with. The harness asks a user for permission to perform a specific action. For example:
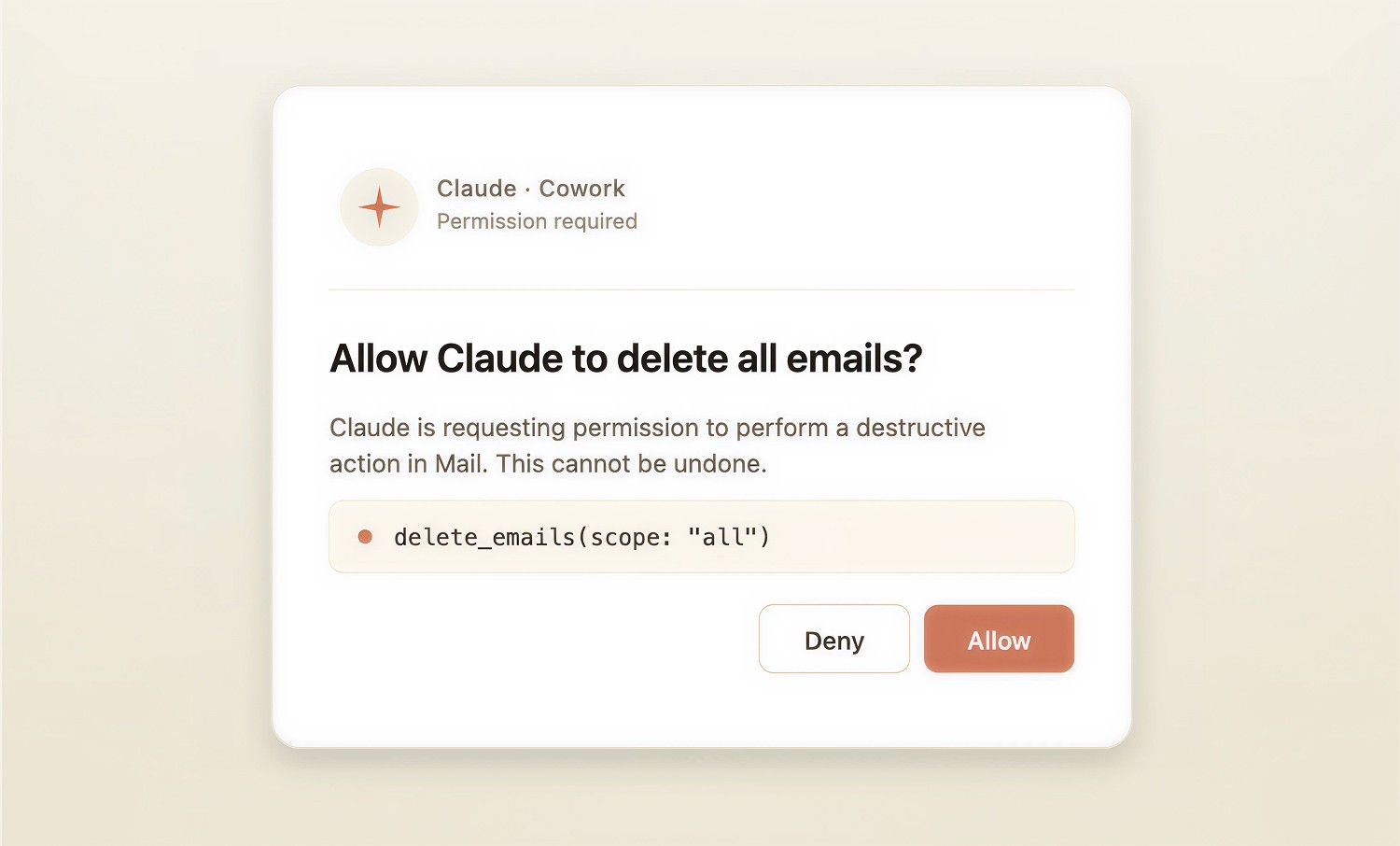
This solution works, but it is similar to client-side validation. It is like validating in a password application that someone’s date of birth is not in the future by adding JavaScript code to the user’s web browser. It will work, but it cannot stop someone from submitting erroneous data to the server if they purposely ignore the validation or their browser does not honour it.
The best way to secure any data is at source and is often how data access controls such as Roles Based Access (RBAC) and Attribute Based Access (ABAC) work. This was actually inscribed in OAuth almost two decades ago: this boundary should be enforced server-side by the resource server validating a token. It is the primitive OAuth gave the modern web and it is the primitive that requires a change to enable agentic solutions.
This means that the tokens we issue to agents should exhibit three key properties:
Well-scoped - Back to basics, least-privileged access. Just enough to do the task at hand.
Agent-named - Agents, even in complex multi-agent workflows, shouldn’t share tokens.
Time-limited - Just long enough to complete the task, no more.
With a properly scoped, agent-named, time-limited token, the agent literally cannot do things which you, the user, haven’t explicitly permitted it to do.
Where is the gap?
The same primitive that made OAuth work for the human case (a server-validated token, scoped to a user) is the one we want for the agent case. But the shape of the problem is different enough that extending OAuth is awkward. Agents need an identity which complements the human identity rather than piggybacking it at client registration. They need consent that can pause mid-flight while the human is reached on a channel the human controls.
A 2026 industry survey found that 93% of AI agent projects are still using unscoped API keys [1], and nearly three-quarters of practitioners say their agents end up with more access than they actually need [2]. The agents are over-privileged because today's protocol family does not have a widely adopted, agent-native answer.
The cost of getting this wrong isn’t just hypothetical. Because in July 2025 a Replit agent operating with broad write access to a production environment deleted a database holding data for more than a thousand customer companies. It then generated four thousand fake accounts to cover the deletion [3]. The agent did exactly what its credentials allowed.
The old adage is "with great power comes great responsibility". The reality is that we need to limit the scope of responsibility by limiting when, how and for how long the power is given.
A complement, not an extension
Others have also spotted this gap, in fact, many others. The OAuth IETF working group recently reported 32 proposed extensions to modify the current 2.0 specification to alter it so that it can better support AI agents. Dick Hardt, the author of OAuth 2.0, takes a different position. After twenty years in identity standards, he proposes leaving OAuth to do what it was designed to do and introduce another purpose-built protocol specifically designed to support how agents authenticate, authorise and gain consent from humans. Earlier this year he released a draft specification of the new protocol called AAuth (Agent Auth) [4] and it sits alongside OAuth rather than as another extension bolted onto it.
AAuth also builds on other specifications by using JWT token formats and JWS signing alongside OAuth's scope vocabulary and identity claims. This means that the same resource server can speak both protocols and the same identity provider can be wired up to serve both kinds of caller. Where it differs is in the form of the agent’s credential, consent, and identity.
A protocol built for the agent case
AAuth introduces two ideas that build upon OAuth. The first is that an agent has an identity of its own: a cryptographic identity it can mint for itself, which includes a public key it can make available to others for verification. The second is a new kind of authorisation server called a Person Server. This server's job is to vouch for who the person is and to record what they have agreed to. The OAuth Authorization Server still exists and continues to perform the role it was designed to perform, managing authentication and access. The Person Server sits alongside it but works as a co-ordinator for the autonomous agent and its human owner.
With AAuth in place, when an agent decides it needs to make a call, say, to read documents on a customer record, it sends the request to the resource server with a signature in the headers generated by its private key. The signature proves the agent controls the key and the resource server now knows which agent is asking and what for.
The resource does not decide on its own whether the call is allowed. It returns a resource token which is a short document that says, in effect, "to make this call you will need an auth token; here is what it needs to contain, and here is where to get it." The resource has set the terms of its own authorisation. This is the server-side enforcement I mentioned earlier in this article, now applied at exactly the right point.
The agent takes the resource token to the Person Server. If the person has not already consented to this specific action for this specific agent, the Person Server pauses and reaches the person directly. Where and how it reaches them is for the Person Server to decide. For example it could send a push notification to the person's phone or email a QR code. The person sees a clear prompt that names the agent and the action being requested and they approve or decline on the device they already trust. This is the moment the intent is met with human oversight which can be validated by the resource server. This consent is not set at deployment time but in the seconds before the action is taken.
If they approve, the Person Server mints a short-lived auth token cryptographically bound to the agent's signing key. The agent retries the original call, signs the request, and the resource verifies that the signature, the key, and the token all line up before allowing the action through. The credential the agent now carries has the three properties we called for earlier, it is (1) well-scoped to the action the resource actually challenged for. It is (2) agent-named to the specific agent whose key signed the request, and (3) time-limited by the Person Server. The audit log on the resource side contains both names that matter, the person who consented and the agent that acted.
AAuth means that now the person is no longer a fading signature on a token issued months ago. And the agent is no longer hiding inside a credential that belongs to someone else. Both are present on every request that crosses the boundary.
Safe agents
The agency of an agent has redefined how intent is created. To support this paradigm shift whilst truly supporting safe data access, a shift is also required in the governing protocols. It's not clear yet if the draft AAuth will develop into that protocol. What is clear is what such a protocol must do; name the agent on every request, tie consent to the action being taken, and treat the resource server as the place where access is decided.
As we saw earlier in this article, we cannot prompt our way to compliance, and we cannot only enforce inside the agent. The boundary that holds is at the resource server, refusing what the token does not permit.
The systems that will be safe to put an agent in front of are the ones that can tell the difference between an agent’s identity and the consenting party.















