

Your AI looks impressive on paper. In practice, it struggles with the work your specialists handle daily.
We're seeing this gap for organisations deploying general-purpose models in specialist contexts. The issue isn't the technology, it's how we're training it. Let's explore why measurement alone won't close this gap, and what actually works.
The performance gap nobody wants to discuss
Here's a scenario you'll recognise: You've hired a legal expert called Sam. Top of their class at Law school, credentials that look flawless. Sam starts work but the quality isn't there. Basic judgement calls miss the mark. Context gets overlooked. Work needs constant revision. You investigate. Sam had access to all of his exam questions & answers beforehand. They understand legal concepts but have never practised law under real conditions. They memorised patterns, not mastery.
That's where general-purpose AI models are right now. Models perform well on public benchmarks, but public benchmarks have a credibility issue. Models score impressively on standardised tests whilst struggling with actual work. Two problems explain this gap.
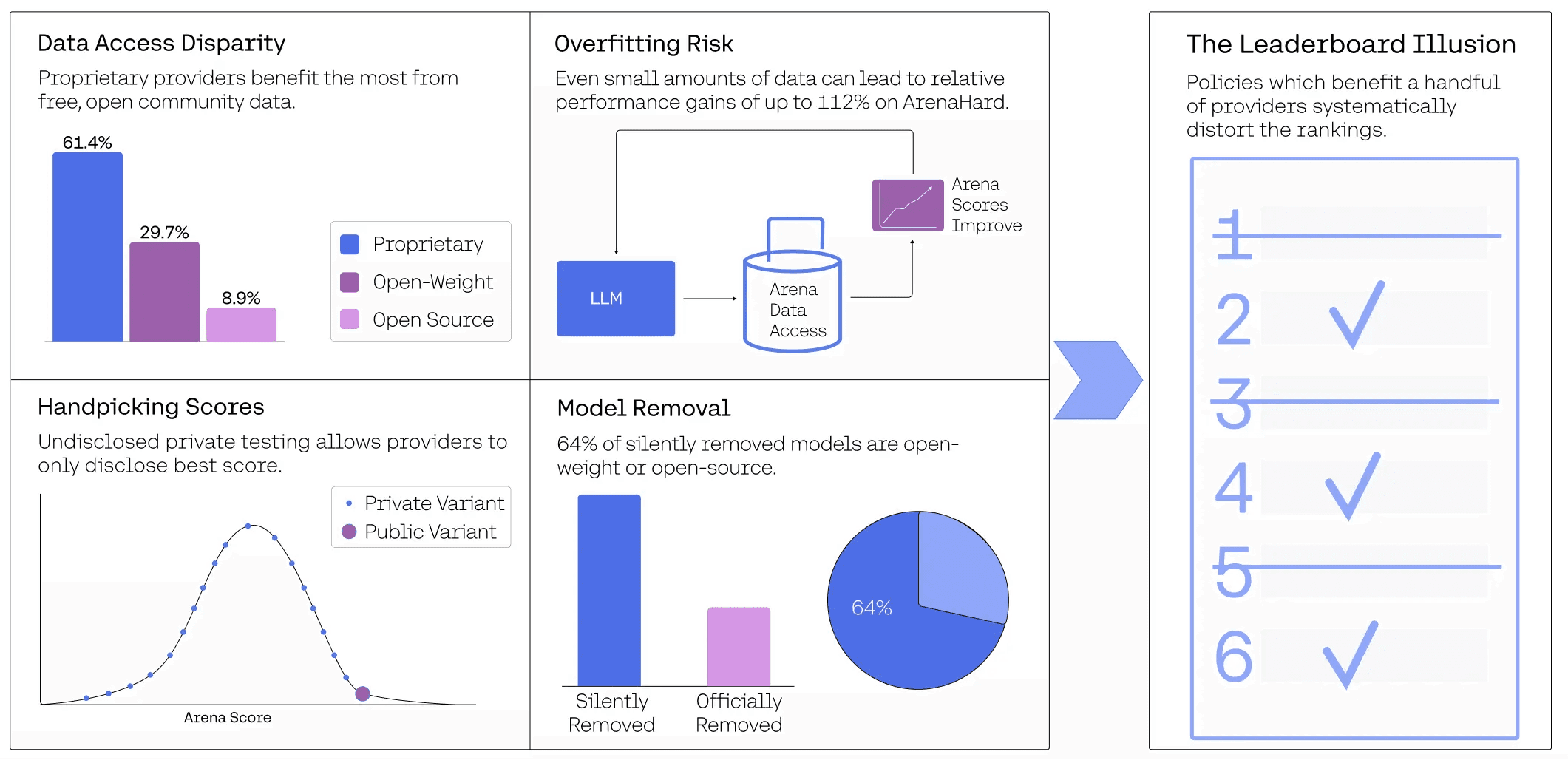
Source: The Leaderboard Illusion
First, selective reporting distorts rankings. The research paper The Leaderboard Illusion documents how private testing and strategic submission timing creates artificial performance hierarchies on platforms like Chatbot Arena. Scores become marketing metrics rather than capability measures.
Second, data contamination undermines validity. Popular benchmarks rely on publicly available datasets that models encountered during training. High scores often reflect memorisation rather than capability.
Your AI performs brilliantly on demonstrations. Then it meets real work and fails in ways that surprise everyone.
Training that mirrors real work
You decide to invest in developing Sam properly. You pair them with your best people. They learn your business context, shadow experts, get feedback on real cases, refine their judgement through practice.
In AI, this is post-training and reinforcement learning. We're working with organisations to build this capability across three approaches:
1.Build your own benchmark: test real performance
Sam's exam scores told you nothing useful. You need to test their performance on your actual cases. Can they draft a contract that meets your standards? Navigate your compliance requirements? Handle the nuances of your jurisdiction?
The same applies to AI. Off-the-shelf benchmarks can't tell you if a model will work in your finance compliance workflows, your healthcare documentation, or your logistics planning. The language is different, the reasoning patterns are different, the acceptable error margins are different.
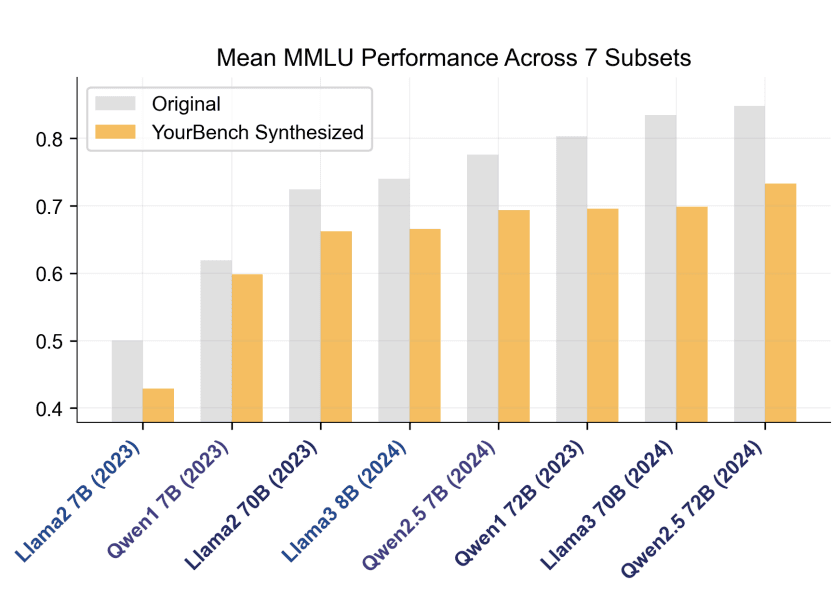
Source: Hugging Face - Your Bench - Easy Custom Evaluation Sets for Everyone
Custom benchmarks shift the question from "how smart is this model?" to "can this model do our work?" Using tools like Your Bench you can build evaluation datasets directly from your operational data real cases your teams handle, actual workflows your systems need to support, genuine complexity your domain requires.
How it works: Build Your Own Benchmark (BYOB) frameworks let organisations create evaluation datasets from their own operational data. Instead of testing models against generic questions, you test them against real examples from your workflows this reveals how models perform on your specific work, not idealised test cases.
What changes: You get an accurate assessment of model capabilities against your actual requirements. This clarity lets you identify where models can deploy safely without further training, and where post-training is essential. Trust becomes evidence-based rather than assumed.
2. Reinforcement Learning from Human Feedback (RHLF) : learn from your best
You pair Sam with your best solicitors for mentoring. They review Sam's work, explain what's strong and weak, share the judgement calls that come from experience. Sam learns your organisation's standards from the people who define them.
AI learns the same way. Your best people know when a compliance analysis is thorough enough, when a customer interaction needs escalation, when a codebase refactor will cause problems. That knowledge usually stays trapped in their heads.
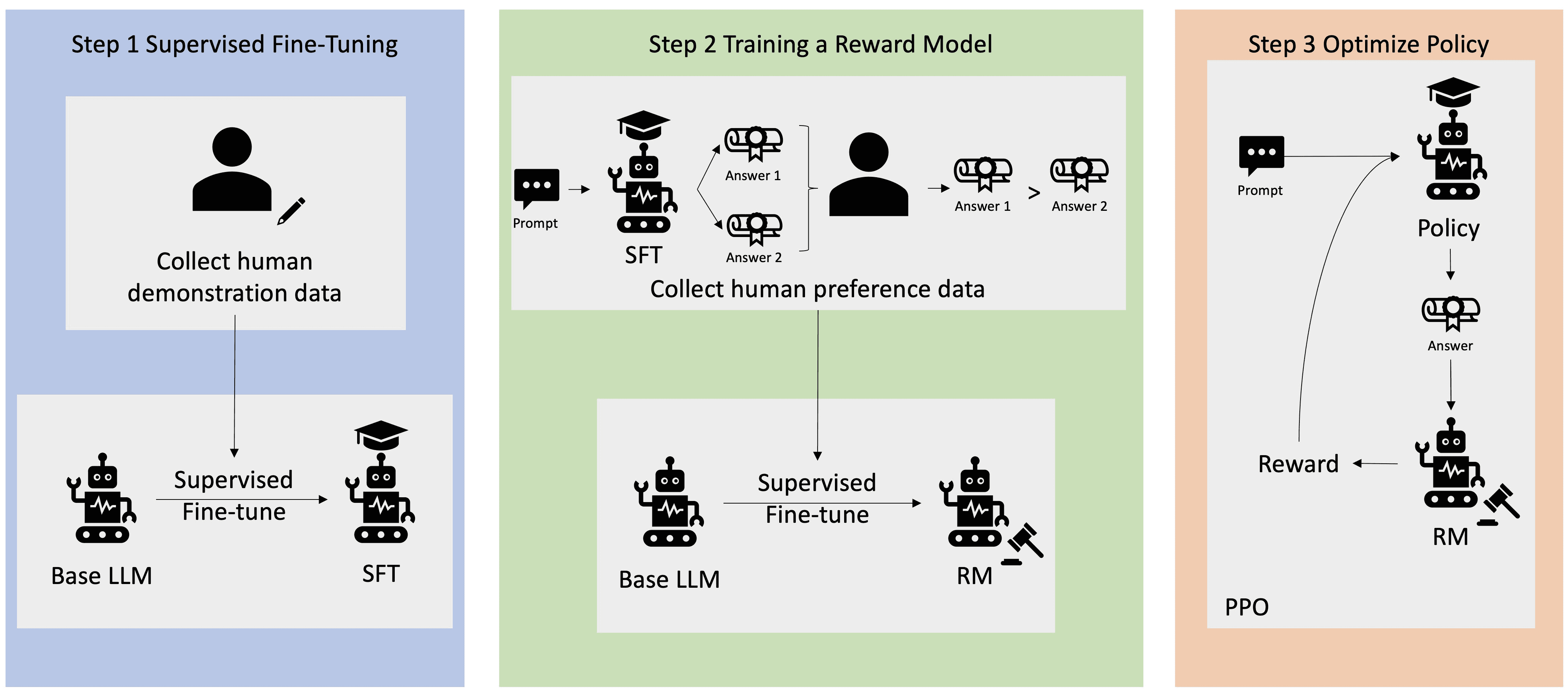
Source: AWS - What is RLHF
Reinforcement learning from human feedback captures this. Your experts review AI outputs, mark what's good and what's not, explain why. The AI learns your organisation's standards, not generic standards.
How it works: Reinforcement Learning from Human Feedback (RLHF) works by showing experts AI-generated outputs and asking them to rate or rank the quality. These ratings train a separate model that learns to predict what your experts consider good work. This "reward model" then guides the AI's training, steering it towards outputs that match your organisation's standards.
What changes: You harness your best people's knowledge and make it accessible across the organisation through refined models. What your top experts understand becomes available to your entire team. Expertise scales beyond individual capacity.
3.RL training environments: practice before production
You don't throw Sam into high-stakes live cases immediately. You create a safe environment: simulated client scenarios, practice negotiations, mock compliance reviews. Sam handles progressively complex situations, gets feedback, refines their approach. They build judgement through experience before the work has real consequences.
AI needs the same safe space to learn. RL training environments create artificial versions of real work scenarios. Models get placed into simulated environments and complete objectives: debugging an application, refactoring a codebase, navigating a customer support escalation, building a compliance report. Their work gets graded. Those grades become training signals.
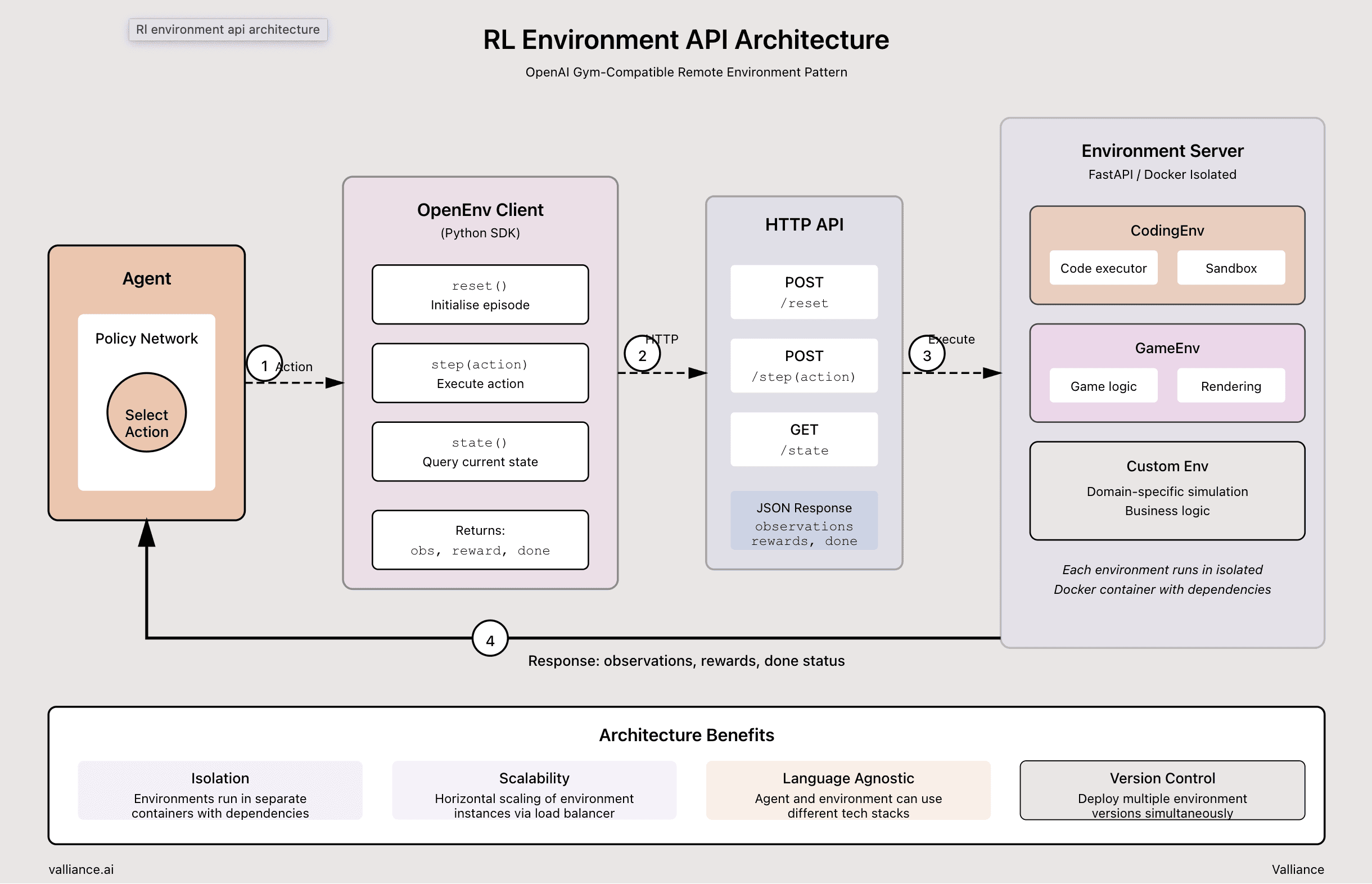
Ref: OpenEnv - An interface library for RL post training with environments.
RL environments are cutting-edge techniques being pioneered by frontier labs to improve model performance, they are investing billions of dollars into building the infrastructure to scale RL training environments.
“All the big AI labs are building RL environments in-house. But as you can imagine, creating these datasets is very complex, so AI labs are also looking at third party vendors that can create high quality environments and evaluations. ”
Already we are starting to see an ecosystem of well funded startups like Prime Intellect who are building RL Environment Hubs so not just frontier labs have access to this technique and frontier labs like Meta realeasing open source tools like OpenEnv.
Where we're seeing this deployed:
Coding and Software Development: Simulated IDEs where models practise debugging before touching production code.
Customer Support: Dialogue environments that model escalation logic, tone sensitivity, brand compliance.
Browser and System Use: Controlled environments that train procedural reliability across dashboards and tools.
Knowledge Retrieval and Reasoning: Simulations that reward factual precision and verifiable synthesis.
How it works: Think of it as a flight simulator for AI. Models practise tasks in environments that mirror your work conditions. They attempt tasks repeatedly, get scored on success, and improve their approach. Safe practice in simulation builds real capability for deployment.
What changes: Your AI develops capability without operational risk. Models practise through thousands of simulated scenarios that mirror your work's complexity. Trust emerges from demonstrated performance in conditions that reflect reality, not promises about generic capability. You deploy with confidence built on evidence.
What this means for your teams
We're not replacing expertise with AI. We're training AI on your expertise. Knowledge becomes accessible at scale when AI systems are trained on your work of your best people:
Your experts' knowledge scales. The patterns your experienced people recognise get encoded through reinforcement learning. Junior team members working with these models access senior-level judgement built on your organisation's specific standards.
Quality becomes consistent. AI trained in your environments learns what "good enough" means in your context. Outputs reflect your benchmarks, not generic training data.
Learning curves compress. A junior analyst supported by AI trained on your cases gets feedback shaped by how your best people handle complexity. They're learning from your organisation's experience.
Your specialists focus on what matters. Well-trained AI handles pattern-matching and standard analysis. Your experts focus on edge cases, strategic decisions, complex situations that require human insight.
Sam, six months later
Sam's work quality has transformed. Not because their credentials changed, but because they've been trained on real cases, mentored by your best people, given feedback that refined their judgement through practice. They understand your organisation's specific standards, context, and complexity.
The shift from generic models to AI trained on your expertise changes what's possible for your teams. Let's explore how we can reshape your organisation's approach to building AI that you can trust to do complex work.



















